Lerneinheit Kapitel 1: Begriffe, Definiton und Konzepte
Was ist künstliche Intelligenz
Geprägt wurde der Begriff Künstliche Intelligenz (Englisch: Artificial Intelligence) bereits Mitte der 1950er Jahre. Aus Ideen verschiedener Wissenschaftler:innen zur Automatisierung menschlicher Denkprozesse durch technische Systeme entwickelte sich ein eigenes Fachgebiet, welches unter dem Schirmbegriff Künstliche Intelligenz Arbeiten zahlreicher Disziplinen vereint, wie beispielsweise der Informatik, Psychologie, Neurowissenschaft, Mathematik, Logik, Kommunikationswissenschaft, Philosophie und Linguistik.
Aufgrund dieser diversen Forschungs- und Anwendungslandschaft, den unterschiedlichen Einflüssen der Disziplinen sowie dem kontinuierlichen technischen Fortschritt unterliegt der Begriff KI einem ständigen Wandel. Im Zentrum des Begriffs steht das Verständnis, dass KI sich damit befasst, mittels Computersystemen Probleme zu lösen, für die bisher menschliche Intelligenz benötigt wurde. Technische Systeme sollen mit einer Art von Wahrnehmung, Denken und Handeln ausgestattet werden, um (neue) Probleme selbstständig erkennen und lösen zu können. Darüber hinaus reichen die Konzepte von präzisen technischen Systemdefinitionen bis hin zu philosophischen Abhandlungen über maschinelles Bewusstsein. Zudem ist zu unterscheiden, dass KI in Industrie, Forschung und Politik entweder über die zu erzielenden Anwendungen oder den Blick auf die wissenschaftlichen Grundlagen definiert wird.
Das Europäische Parlament formuliert beispielsweise eine knappe auf technische Fähigkeiten begrenzte Definition:
Künstliche Intelligenz ist die Fähigkeit einer Maschine, menschliche Fähigkeiten wie logisches Denken, Lernen, Planen und Kreativität zu imitieren.”
Nils Nilsson, der an der Stanford University zu KI forscht, orientiert sich in seinem Begriffsverständnis am grundlegenden Intelligenzbegriff:
Künstliche Intelligenz ist jene Tätigkeit, die darauf ausgerichtet ist, Maschinen intelligent zu machen, und Intelligenz ist jene Eigenschaft, die es einer Einheit ermöglicht, in ihrer Umgebung angemessen und vorausschauend zu funktionieren“
Stuart Russell und Peter Norvig, die Autoren eines der Standardwerke im Bereich Künstliche Intelligenz (Artificial Intelligence: A modern approach; dt.: Künstliche Intelligenz: Ein moderner Ansatz) schlagen eine systemische Sicht auf KI vor:
(intelligente) Handlungseinheiten, die Vorgaben aus der Umwelt erhalten und Maßnahmen ergreifen. Jede dieser Handlungseinheiten wird durch eine Funktion implementiert, die Wahrnehmungen auf Aktionen abbildet. Wir betrachten verschiedene Möglichkeiten, diese Funktionen darzustellen, wie z.B. Produktionssysteme, reaktive Handlungseinheiten, logische Planer, neuronale Netze und entscheidungstheoretische Systeme.”
Karen Hao hat 2018 im MIT Magazin Technology Review ein Flowchart veröffentlicht, welches eine Einschätzung ermöglicht, ob und welche Art an KI-Technologie in einem System verwendet wird. So kann beispielsweise bestimmt werden, ob es sich um ein „sehendes“ KI-System handelt oder ob lediglich Kameras verbaut wurden – intelligent wird ein solches System erst dadurch, dass eine Identifizierung von Objekten durch Computer Vision und Image Processing erfolgt.
Arten von KI
Heutige KI-Anwendungen sind bereits ziemlich „schlau“. Allerdings gibt es große Unterschiede zwischen den Systemen – je nachdem, welche Aufgaben zu erledigen sind. Den Umfang an Aufgaben, den ein KI-System durchführen kann, ist mit unterschiedlicher Verwendung und „Grad an Intelligenz“ assoziiert. Basierend auf dem Umfang und den Arten an Fähigkeiten (bzw. deren Nähe zur menschlichen Intelligenz) von KI-Systemen lässt sich KI in zwei Gruppen einteilen: schwache und starke KI.
Schwache KI
Durch eine schwache KI (auch als narrow KI bezeichnet) können innerhalb eines begrenzten Rahmens klar spezifizierte Aufgaben mit einer festgelegten Methodik bewältigt werden, um komplexere, aber wiederkehrende und genau definierte Probleme zu lösen. Diese besitzt keine Kreativität. Ihre Lernfähigkeiten sind nicht universell und selbständig, sondern zumeist reduziert. Schwache KI besteht zum Beispiel aus dem Trainieren von Erkennungsmustern (Machine Learning) oder dem Abgleichen und Durchsuchen von großen Datenmengen. Bei schwacher KI ist keine Kreativität oder menschenähnliches Problemlösen, Lernen oder Entscheidungsfinden im Spiel. Sie kann aber insbesondere in der Automatisierung und im Controlling von Prozessen, aber auch in der Spracherkennung und -verarbeitung verwendet werden. Beispiele für solche Systeme und Aufgaben sind Bild- oder Spracherkennung, Textübersetzungen oder auch Navigationssysteme.
Starke KI
Bisher gab und gibt es (noch) keine Realisierung einer starken KI (auch als broad KI bezeichnet), da die Technologie noch nicht ausgereift genug ist. Die Zielsetzung des Konzeptes der starken KI ist es, dass natürliche und künstliche Agenten (bspw. Menschen und Roboter) beim Arbeiten im selben Handlungsfeld ein gemeinsames Verständnis aufbauen können. So könnte beispielsweise eine effiziente Mensch-Maschine-Kollaboration ermöglicht werden. Eine starke KI kann selbständig Aufgabenstellungen erkennen und definieren und sich hierfür Wissen der entsprechenden Anwendungsdomäne erarbeiten und aufbauen. Hierbei werden Probleme untersucht und analysiert, um zu einer adäquaten Lösung zu finden – die auch neu bzw. kreativ sein kann. Wann in Zukunft eine starke KI entwickelt werden kann, ist noch offen und von vielen verschiedenen Faktoren abhängig. Meist geht es aber weniger darum, ein System zu entwickeln, das die Bedingungen von starker KI erfüllt, sondern letztendlich Maschinen zur Lösung mehrschichtiger, nicht eng definierter Probleme zu entwickeln. So ist eines der Ziele bei der Entwicklung von KI die Schaffung autonomer Systeme, die über einen gewissen Grad an allgemeiner Intelligenz verfügen.
Wie funktionieren KI-Systeme
Aus technischer Sicht basieren KI-Systeme auf Algorithmen. Ein Algorithmus ist eine eindeutige Handlungsanweisung, die der Lösung eines spezifischen Problems dient und eindeutig reproduzierbar ist. Ein Algorithmus kann mit dem Backen nach einem Rezept verglichen werden. Der Algorithmus erhält eine Eingabe bzw. einen Input (Backzutaten). Nach der Ausführung der Handlungsanweisungen (Rezept) erfolgt eine Ausgabe bzw. ein Output (fertiger Kuchen). In der Informatik werden Algorithmen in Form von Programmiersprachen geschrieben.
Machine Learning
Traditionelle („nichtlernende“) Software besteht aus einer Reihe von Regeln, die von Menschen erstellt wurden und von Maschinen ausgeführt werden, um eine gewünschte Aufgabe zu erfüllen.
Beim Machine Learning (ML, Maschinelles Lernen), als ein Teilgebiet der Künstlichen Intelligenz, liegt der Schwerpunkt auf Software, die eigenständig Regeln definiert, um zu einer vorgegebenen Ausgabe zu gelangen. Machine Learning ist ein Methoden- bzw. ein Werkzeugkasten, welcher verschiedene Ansätze der Datenverarbeitung und Modellerstellung umfasst. Der gemeinsame kleinste Nenner dieser Ansätze ist, dass ein Algorithmus aus Daten „lernt“ und einen individuellen Lösungsweg findet.
Mittels Maschinellem Lernen kann automatisiert Wissen generiert werden. Zudem können Algorithmen trainiert, Zusammenhänge identifiziert und unbekannte Muster in vorliegenden Datenmengen erkannt werden. So sind auf Machine Learning basierende Systeme in der Lage, Lösungen für Probleme zu finden. Die aus den Daten gewonnenen Erkenntnisse lassen sich verallgemeinern und für neue Problemlösungen oder für die Analyse von bisher unbekannten Daten verwenden, um so Vorhersagen zu treffen und Prozesse zu optimieren.
Eine notwendige Voraussetzung für Maschinelles Lernen ist die Bereitstellung von Trainingsdaten. Diese Daten müssen sorgsam ausgewählt werden, da die Qualität und Vielfältigkeit maßgeblich über die Güte des Machine Learning Modells entscheiden. Es ist eine relevante Stellschraube durch welche Menschen (Programmierer:innen, Data Scientists usw.) Einfluss auf KI-Systeme nehmen.
Maschinelles Lernen findet in unterschiedlichen Bereichen Anwendung:
Computer Vision
Erkennen visueller Eingangssignale (bspw. Röntgenbildanalyse)
Natural Language Processing

Verarbeitung natürlicher Sprache zur Kommunikation zwischen Mensch und Maschine (bspw. Siri oder Alexa) .
.
Durch Spracherkennung zur Emotion – Individualisierte Beratungsgespräche dank KI-Unterstützung
Mehr Infos zum KARL-Projekt
Computer Audition
Mustererkennung in Audiodateien (bspw. Genreerkennung)
Vorhersage (Prediction)
aus Daten vergangener Ereignisse wird auf die Zukunft geschlossen (bspw. Wettervorhersage)
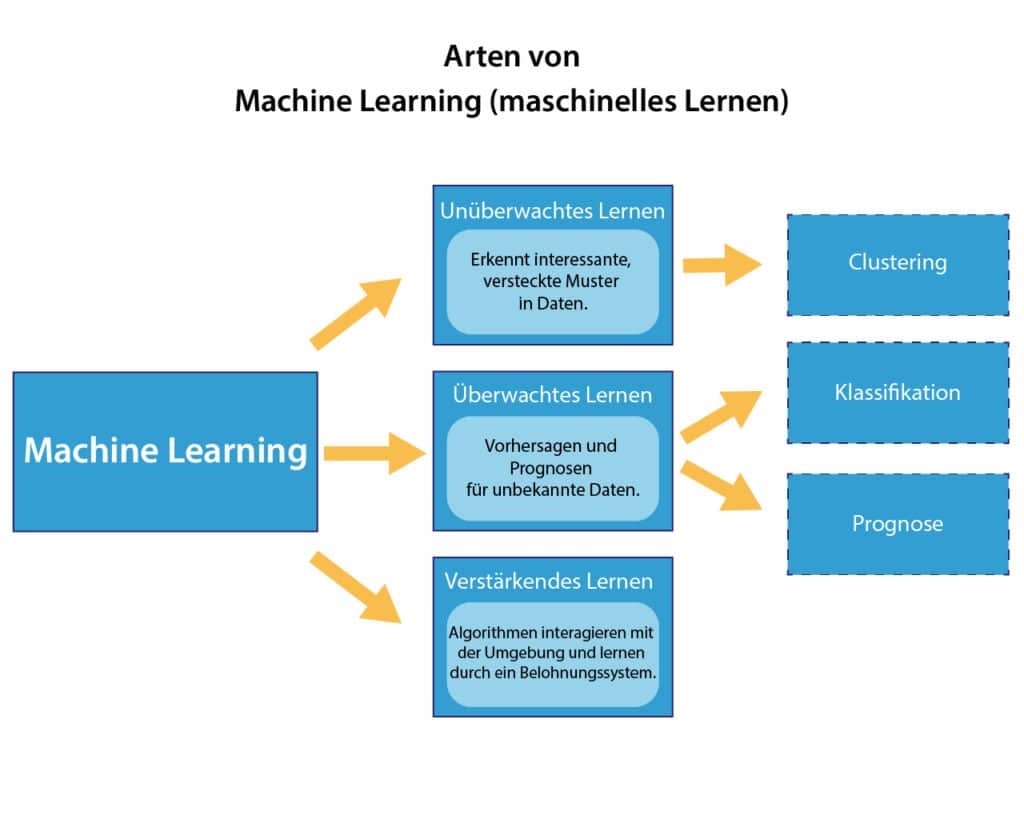
Unüberwachtes vs. überwachtes vs. bestärkendes Lernen
Verschiedene Algorithmen aus dem Bereich des Maschinellen Lernens lassen sich grob in drei Gruppen einteilen: überwachtes Lernen (supervised learning), unüberwachtes Lernen (unsupervised learning) und bestärkendes Lernen (reinforcement learning).
Überwachtes Lernen
Beim überwachten Lernen besteht die Datenbasis, die durch einen Algorithmus verarbeitet wird und auf der er trainiert wird, aus gekennzeichneten bzw. bekannten Daten. Es gibt außerdem eine klare Zielvariable. Der Algorithmus versucht, Zusammenhänge und Abhängigkeiten in den Daten zu erlernen, die diese Variable am besten vorhersagen. Die Zielvariable kann eine Klasse (bspw. Auto vs. Schiff) oder ein numerischer Wert (bspw. Umsatz für den nächsten Monat) sein. Nach dem Training wird die Qualität der Vorhersage bewertet, um anschließend die erlernten Muster auf unbekannte Daten anzuwenden und Prognosen sowie Vorhersagen zu erstellen.
In der Praxis wird überwachtes Lernen in der Regel entweder zur Klassifizierung (= Einteilung der Daten anhand vorgegebener Kategorien) oder für Regressionen (= Vorhersage der Häufigkeit eines Wertes) genutzt. Beispiele können sein:
- Vorhersage von Stromverbrauch für einen Zeitraum X (Regression)
- Berechnung von Ausfallwahrscheinlichkeiten von Maschinen (Regression)
- Objekt- und Texterkennung (Klassifikation)
Unüberwachtes Lernen
Unüberwachtes Lernen bezeichnet eine Methode, bei der ein Algorithmus lernt, selbständig und ohne Überwachung, Muster und Zusammenhänge in Daten explorativ zu erkennen. Die Modelle werden ohne Zielvariable trainiert und in der Praxis genutzt…
…zur Dimensionsreduktion von Daten (Vereinfachung eines Datensatzes ohne Informationsverlust, um z.B. die Mustererkennung zu erleichtern; Bsp. aus der Praxis: Extraktion von Regeln und Strukturen),
…für Clusteranalysen (Erkennen von Mustern in Daten und anschließende Kategorisierung anhand ähnlicher Muster; Bsp. aus der Praxis: Kunden- und Marktsegmentierung),
…für Assoziationsanalysen (Erkennen von Zusammenhängen) und
…zur Bestimmung von Ausreißern.
Überblick: Unterschiede zwischen überwachtem und unüberwachtem Lernen:
| Überwachtes Lernen | Unüberwachtes Lernen | |
| Prozess zwischen Eingabe und Ausgabe | Eingabe- und Ausgabedaten sind gegeben | Nur Eingabedaten sind gegeben |
| Eingabedaten | Bekannte Beispieldaten und Zielvariable | Unbekannte Beispieldaten ohne Zielvariable |
| Einsatz in der Praxis | Training passiert vor dem Einsatz | Kann in Echtzeit genutzt werden |
Bestärkendes Lernen
Bestärkendes Lernen ist eine besondere Form des Maschinellen Lernens und basiert auf einer Trial-and-Error-Logik (Versuch und Irrtum). Das bedeutet, die Algorithmen werden durch eine Kostenfunktion oder ein Belohnungssystem bewertet, sodass sie selbständig eine Strategie zur Problemlösung erlernen – stets mit dem Ziel die Belohnung zu maximieren. Bei verstärkendem Lernen wird dem Algorithmus nicht gezeigt, welche Aktion oder Handlung in welcher Situation die richtige ist, sondern er erhält durch die Kostenfunktion eine positive oder negative Rückmeldung. Anhand der Kostenfunktion wird dann eingeschätzt, welche Aktion zu welchem Zeitpunkt die Richtige ist. Der entscheidende Unterschied zu überwachtem und unüberwachtem Lernen ist, dass das bestärkende Lernen vorab keine Beispieldaten benötigt. Die Algorithmen können in einer Simulationsumgebung in vielen iterativen Schritten eine eigene Strategie entwickeln.
In der Praxis wird bestärkendes Lernen beispielsweise in der Personalisierung von Feeds und Werbung oder auch zur Verkehrssteuerung eingesetzt.
Deep Learning
Deep Learning (DL) ist ein Teilbereich des Maschinellen Lernens und eine spezielle Methode zur Informationsverarbeitung.
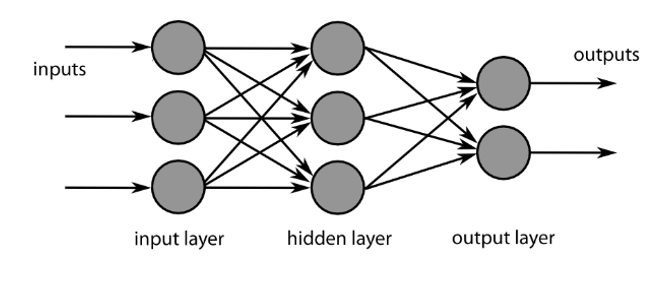
Die Funktionsweise von Deep Learning basiert auf der Verwendung künstlicher neuronaler Netze (KNN). Hierunter versteht man Algorithmen, die dem menschlichen Gehirn nachempfunden sind und aus Knoten, den so genannten Neuronen, aufgebaut sind. Diese Knoten sind in drei Schichten angeordnet: Die Eingabeschicht (Input Layer) nimmt die Eingabe entgegen. Darauf folgt eine oder mehrere versteckte Schicht(en) (Hidden Layers). Je „tiefer“ bzw. komplexer das Netz aufgebaut ist, desto mehr dieser Schichten enthält es. Das gleiche gilt auch andersherum: Je mehr Neuronen und Schichten ein neuronales Netz umfasst, desto komplexere Sachverhalte können dargestellt werden. Die letzte Schicht stellt die Ausgabeschicht (Output Layer) dar. Besteht das künstliche neuronale Netz aus insgesamt mehr als drei Schichten, so spricht man von Deep Learning-Algorithmen. Die meisten Deep Learning-Algorithmen sind tiefe neuronale Netze (Deep Neural Networks, kurz: DNN), die sich durch mehrere verborgene Schichten zwischen der Eingabe- und der Ausgabeschicht auszeichnen.
DL-Algorithmen sind in der Lage, unstrukturierte Informationen wie Texte, Bilder, Töne und Videos in numerische Werte umzuwandeln und zu verarbeiten. Beim Lernvorgang greift der Mensch nicht ein, das Analysieren wird dem Computer überlassen, wodurch Deep-Learning-Modelle in der Lage sind, von sich aus zu lernen. Bereits erlernte Fähigkeiten werden immer wieder mit neuen Inhalten angereichert und verknüpft, wodurch das System stetig lernt. Die extrahierten Informationen lassen sich dann zur Mustererkennung, Vorhersage oder zum weiteren Lernen verwenden.
Deep Learning kommt vor allem für Anwendungen zum Einsatz, die auf großen Datenbeständen basieren und große Datensätze nach Mustern und Trends untersucht werden.
Beispiele aus der Praxis:
Autonomes Fahren
Erkennung von Objekten, wie bspw. Stoppschilder oder Ampeln und Unterscheidung der Objekte von Fußgänger.

KARL gibt spannende Einblicke in die Sichtweise von Sicherheitsfahrer:innen auf die Assistenzfunktionen in autonom fahrenden Bus-Shuttles
Medizin
Erkennung von Krebszellen, Identifikation von Krankheitsfällen
Landwirtschaft
Differenzierung zwischen Kulturpflanze und Unkraut zur selektiven Verwendung von Pestiziden und Herbiziden
Luft- und Raumfahrt
Erkennung von Objekten zur Identifikation sicherer bzw. gefährlicher Zonen
Elektronik
Automatisiertes Hören und Sprechen, um auf Stimme des Anwenders zu reagieren und Wünsche zu erkennen
Überblick: Unterschiede zwischen Machine Learning und Deep Learning:
| Machine learning | Deep learning | |
| Struktur der Daten | Strukturierte Daten | Unstrukturierte Daten |
| Größe des Datensatzes | Klein bis mittel | Groß |
| Benötigte Hardware | EInfache Hardware | Leistungsstarke Hardware |
| Verständlichkeit der Ergebnisse durch den Menschen | Leichte bis hin zu fast unmöglicher Interpretation der Ergabnisse durch den Menschen | Schwierige und oft unmöglicher Interpretation |
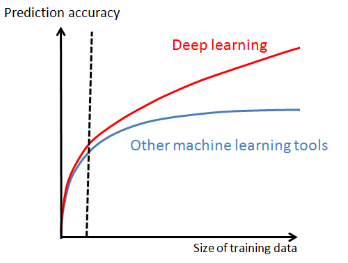
Deep Learning ist zwar technisch und ressourcenseitig anspruchsvoller, doch ein Vorteil von Deep Learning gegenüber den anderen Arten von Machine Learning ist die höhere Genauigkeit der Ergebnisse bei steigender Größe des Datensatzes.